

こんにちは。iQeda [@iQeeeda] です。
今回はデータ構造のひとつ「連結リスト」を解説します。
たくさん問題も解くので、エンジニア面談の傾向と対策になると思います。
目次
連結リストとは

連結リストとは、ノードオブジェクトの並びを表した「データ構造」です。
- 単方向連結リスト (片方向連結リスト)
- 各ノードは次のノードの位置を参照します
- 双方向連結リスト (両方向連結リスト)
- 各ノードは次のノード・前のノード、その両方の位置を参照します
配列とは異なり、連結リストは index 指定でいきなり要素にアクセスする機能がありません。
k 番目のノードを見つけたい場合、
k 個分のノードを走査しないといけない…というデメリットがあります。
よって、ノードアクセスは「一定時間で行えない」のですが、
ノードの追加・先頭からのノード削除は「一定時間で行える」というメリットがあります。
単方向連結リストの生成
class Node {
Node next = null;
int data;
// コンストラクタ
public Node(int d) {
data = d;
}
// 新しいノードを追加する関数
void appendToTail(int d) {
// 新しいノードインスタンスを作成
Node end = new Node(d);
// このインスタンス自身
Node n = this;
// 最後のノードまでループを回す ※ 最後のノードの next は null
while (n.next != null) {
n = n.next;
}
n.next = end;
}
}
連結リストでは「先頭ノードの参照を通じて、全体にアクセス」します。
もし連結リストの先頭ノードが変更された場合、
後続ノードが古い先頭ノードを参照したままにならないように注意しましょう。
それを避けるには、Node クラスをラップした LinkedList クラスを作って継承しましょう。
LinkedList のメンバ変数で先頭ノードを管理しておけばよいでしょう。
単方向連結リストから特定のノードを削除する
連結リストの特定ノードの削除は、以下の点に注意してください。
- Null ポインタのチェック
- 先頭 / 末尾のポインタ更新
単方向連結リストから特定のノード n を削除する場合、
1 つ前のノードを prev とすると prev.next の参照先は n から n.next に変更してください。
双方向連結リストの場合なら n.next.prev の参照先も n から n.prev に変更する必要があります。
※ C 言語系の場合、削除したノードのメモリ解放することも忘れないでください。
class Node {
Node next = null;
int data;
// コンストラクタ
public Node(int d) {
data = d;
}
// ノードを削除する関数
Node deleteNode(Node head, int d) {
Node n = head;
/*
* 先頭ノードが削除対象の場合
*/
if (n.data == d) {
// 先頭ノードを next に変更して返却する
return head.next;
}
/*
* 先頭ノード以外が削除対象の場合
*/
// 最後のノードまでループを回す ※ 最後のノードの next は null
while (n.next != null) {
// 次のノードが削除対象と判明した場合
if (n.next.data == d) {
// next を「次の次のノード」に変更する
n.next = n.next.next;
return head;
}
n = n.next;
}
return head;
}
}
ランナーテクニックとは

ランナーとは「第 2 ポインタ」のことです。
これを利用した「ランナーテクニック」は連結リストに関する多くの問題で使われています。
最初から順番に巡回するポインタ A と、
ポインタ A より早く、先の要素から巡回するポインタ B の 2 つを使います。
ランナーテクニックの使い方
a1 → a2 → … → an → b1 → b2 → … → bn
上記、連結リストがあったとして…
a1 → b1 → a2 → b2 → … → an → bn のような順番に変えたいとします。
リストの長さは「偶数」ということは分かっていますが、具体的な長さはわかりません。
答え
このような場合は「連結リストを 1 個ずつ飛ばして巡回する」ポインタ p1 と、
普通に巡回するポインタ p2 を用意しましょう。
もし p1 がリスト末尾に到達したら、p2 はリストの中間地点 b1 にいるはずです。
次に p1 を連結リストの先頭に戻してあげると、p1 は a1 を指して、p2 は b1 を指している状態になるはずです。
あとは交互を縫い合わせるように連結させれば、目的のリストを作成できます。
再帰的アルゴリズムの計算量に注意する

連結リストの問題の多くは「再帰的アルゴリズム」に頼ることになります。
どんなに複雑でも関数の再帰的な呼び出しで実装できます。
しかし再帰的なアルゴリズムでは、再帰の深さを n とすると、少なくともメモリ使用量は O(n) になってしまいます。利用するときは注意しましょう。
連結リストの問題集
重複要素の削除
ソートされていない連結リストから、重複する要素を削除するコードを書いてください。
答え
重複部分を追跡できるようにするためには、単純なハッシュテーブルを用意すれば大丈夫です。
void deleteDups(LinkedListNode n) {
// Java のハッシュテーブルオブジェクト
HashSet<Integer> set = new HashSet<Integer>();
LinkedListNode previous = null;
// 連結リストを巡回する
while (n != null) {
// ハッシュテーブルに重複する要素が見つかったら
if (set.contains(n.data)) {
// previous = n しないことが要素の削除
// next も修正する
previous.next = n.next;
// 連結リストの要素をハッシュテーブルに追加する
} else {
set.add(n.data);
previous = n;
}
n = n.next;
}
}
連結リスト巡回は 1 回で済みます。
要素数 N とすると、計算量は O(N) になります。
もし一時的なバッファが使用できない場合
バッファが確保できない場合は 2 つのポインタを使いましょう。
1 つ目のポインタは「リストの先頭要素」から順番に調べていき、
2 つ目のポインタは「 1 つ目のポインタより後方のすべての要素」を調べるようにします。
要するに 2 重ループを使って、すべての要素の比較を行います。
void deleteDups(LinkedListNode head) {
LinkedListNode current = head;
while (current != null) {
/*
* current より先にあるノードを走査して、
* 同じ値を持つノードがあったら削除する
*/
LinkedListNode runner = current;
while (runner.next != null) {
if (runner.next.data == current.data) {
// runner = runner.next しないことが要素の削除
// next の修正
runner.next = runner.next.next;
} else {
runner = runner.next;
}
}
current = current.next;
}
}
消費メモリは O(1) ですが、計算量は O(N^2) なので注意してください。
後ろから K 番目を返す
単方向連結リストにおいて、
末尾から数えて k 番目の要素を見つけるアルゴリズムを実装してください。
答え
この問題では「再帰・非再帰」の 2 つのアプローチを考えてみます。
ちなみに、連結リストのサイズがわかっている場合
連結リストのサイズがわかっていれば、
後ろから数えて k 番目の要素は リストのサイズ - k 番目でいきなりわかってしまいます。
問題が簡単すぎるため、エンジニア面談などではそんな前提で質問されないと思います。
① 再帰
再帰的な方法は簡潔ですが、最適解にならないことが多いので注意しましょう。
リストの要素数を n とすると消費メモリは O(n) になります。
連結リスト終端までたどり着いたら、カウンター 0 をセットして上位ノードに戻ります。
上位ノードに戻るごとにカウンターを 1 ずつ増やして、上位ノードに戻ります。
カウンターが k になったとき、そのノードこそ後ろから k 番目といえます。
基本は上記の考え方で、再帰的に関数を実行して連結リストを巡回します。
ここでは 3 つの解法 A, B, C を紹介します。
A: 要素を返さない実装
Java では「カウンターの値とノードの index を同時に返却できない」という問題があります。
※ return できるのは 1 つのデータ型だけ
しかし「要素は返却せずに、標準出力するだけでいい」と問題を解釈するのであれば話は簡単です。
関数の戻り値をカウンターの値にするだけです。
int printKthToLast(LinkedListNode head, int k) {
// 連結リストの終端までたどり着いたら、カウンター 0 をセットする
if (head == null) {
return 0;
}
// 再帰実行: カウンター 0 からインクリメントしていく
int index = printKthToLast(head.next, k) + 1;
// 後ろから k 番目に到達したら
if (index == k) {
// 標準出力するだけ (要素は返却しない)
System.out.prinln(k + "th to last node is" + head.data);
}
return index;
}
B: C++ の参照を使った実装
スタックを介して整数値を返す方法があれば、短く・簡単に実装にすることができます。
C++ を使えば「カウンター変数のポインタを渡す」ことで、
ノードの要素を return できるだけではなく、カウンター変数の内容も更新することができます。
// カウンターのポインタを int& i で受け取る
node* nthToLast(node* head, int k, int& i) {
if (head == NULL) {
return NULL;
}
node * nd = nthToLast(head->next, k, i);
i = i + 1;
if (i == k) {
return head;
}
return nd;
}
node* nthToLast(node* head, int k) {
int i = 0;
return nthToLast(head, k, i) {
}
C: ラッパークラスを作る実装
Java で複数の値を返却したい場合、オブジェクトにセットして return するしかありません。
ラッパークラスのメンバ変数にカウンターの値を持たせればよいでしょう。
// ラッパークラス
class Index {
public int value = 0;
}
LinkedListNode kthToLast(LinkedListNode head, int k) {
Index idx = new Index();
return kthToLast(head, k, idx);
}
LinkedListNode kthToLast(LinkedListNode head, int k, Index idx) {
if (head == null) {
return null;
}
LinkedListNode node = kthToLast(head.next, k, idx);
idx.value = idx.value + 1;
if (idx.value == k) {
return head;
}
return node;
}
また、カウンター変数を static にすること解決することもできるでしょう。
あるいはノードとカウンターの値を保持するクラスを作り、
そのクラスのインスタンスを return してもよいでしょう。
いずれにせよ、再帰的なスタックのどの階層においてもノードとカウンターは見えていて、
いつでもそれらを更新できる状態にしておく必要がある…ということです。
② 非再帰 (ループ処理のみ)
ループ処理で実装するのが最適な解法です。
この解法の計算時間は O(n) で、消費メモリは O(1) になります。
ここでは「ランナーテクニック」を利用して、2 つのポインタ p1, p2 を用意します。
p2 はリストの先頭から、p1 はリスト先頭から k ノード進んだ場所に配置します。
この状態で 2 つのポインタを同時に進めると、先に p1 がリストの終端に達します。
そのとき p2 は後ろから数えて k 番目に達していることになります。
LinkedListNode nthToLast(LinkedListNode head, int k) {
// ポインタを 2 つ用意する
LinkedListNode p1 = head;
LinkedListNode p2 = head;
// p1 は k ノード分だけ移動させる
for (int i = 0; i < k; i++) {
// 範囲外のとき
if (p1 == null) return null;
p1 = p1.next
}
/*
* ポインタ p1, p2 を同じペースで進める
* p1 が終端の要素に達したとき p2 は後ろから k 番目の要素に達している
*/
while (p1 != null) {
p1 = p1.next;
p1 = p1.next;
}
return p2;
}
間の要素を削除
単方向連結リストにおいて、間の要素のみアクセス可能とします。
※ 必ずしもちょうど中央というわけではなく「最初と最後の要素以外」という意味
その要素を削除するアルゴリズムを実装してください。
- 例
- 入力: a -> b -> c -> d -> e -> f という連結リストの c が与えられます
- 出力: 何も返しませんが、リストは a -> b -> d -> e -> f のように見えます
答え
いきなり (削除対象の) ノードにアクセスさせられます。
ですが、その対象ノードを削除するのではなく…
- その対象ノードに次のノードの情報を上書きする
- 次のノードだけ削除する
これで OK です。
boolean deleteNode(LinkedListNode n) {
// 失敗
if (n == null || n.next == null) {
return false;
}
LinkedListNode next = n.next;
n.data = next.data;
n.next = next.next;
return true;
}
削除対象のノードが「リスト末尾」だった場合、この解法はそのまま使えません。
その場合はダミーノードを用意する、などで対応可能です。
リストの分割
ある数 x (ピボット) が与えられたとき、連結リストの要素を並び替えて、
x より小さいものが前にくるようにするコードを書いてください。 ※ 昇順にする必要はない
x がリストに含まれる場合、x の値は x より小さい要素の後にある必要があります。
区切り要素の x は右半分のどこに現れてもかまいません。
左半分と右半分のちょうど間にある必要はないということです。
- 例
- 入力: 3 -> 5 -> 8 -> 5 -> 10 -> 2 -> 1 [区切り要素 = 5]
- 出力: 3 -> 1 -> 2 -> 10 -> 5 -> 5 -> 8
答え
配列要素をシフト操作するときは注意してください。
これはとてもコストの大きい処理です。
ですが連結リストの場合はもっとラクになります。
シフト操作・入れ替え操作を行わず、2 つのリストを新しく作成して連結するだけです。
- リスト 1
- x より小さい要素を集めたリストを作成する
- リスト 2
- x 以上の要素を集めたリストを作成する
- リスト 1 + リスト 2
区切値の周辺では要素の移動が行われますが、それ以外の並び順はほとんど変わりません。
/*
* 引数には、連結リストの先頭と・分割に使う数 x が渡される
*/
LinkeListNode partition(LinkedListNode node, int x) {
LinkedListNode beforeStart = null;
LinkedListNode beforeEnd = null;
LinkedListNode afterStart = null;
LinkedListNode afterEnd = null;
while (node != null) {
LinkedListNode next = node.next;
node.next = null;
if (node.data < x) {
/*
* 前半リストの最後にノードを挿入する
*/
if (beforeStart == null) {
beforeStart = node;
beforeEnd = beforeStart;
} else {
beforeEnd.next = node;
beforeEnd = node;
}
} else {
/*
* 後半リストの最後にノードを挿入する
*/
if (afterStart == null) {
afterStart = node;
afterEnd = afterStart;
} else {
afterEnd.next = node;
afterEnd = node;
}
}
node = next;
}
if (beforeStart == null) {
return afterStart;
}
// 前半のリスト・後半のリストをマージする
beforeEnd.next = afterStart;
return beforeStart;
}
しかし、リストに関する変数が 4 つもあるのでバグに悩まされるかもしれませんね。
要素の並び順を気にしないなら
リストの先頭・末尾を大きくなってもいいなら、よりシンプルに書くことができます。
LinkeListNode partition(LinkedListNode node, int x) {
LinkedListNode head = node;
LinkedListNode tail = node;
while (node != null) {
LinkedListNode next = node.next;
if (node.data < x) {
/*
* 区切値より小さいものは先頭に置く
*/
node.next = head;
// 要素を付け加えるごとに更新する
head = node;
} else {
/*
* 区切値より大きいものは末尾に置く
*/
tail.next = node;
// 要素を付け加えるごとに更新する
tail = node;
}
node = next;
}
tail.next = null;
// 先頭ノードが変更されたので、返却する必要がある
return head;
}
リストで表された 2 数の和
各ノードの要素が 1 桁の数である連結リストで表された 2 つの数があります。
一の位がリストの先頭になるように、各位の数は逆順で並んでいます。
このとき 2 つの数の和を求め、
それを連結リストで表したものを返す関数を書いてください。
- 例
- 入力: ( 7 -> 1 -> 6 ) + ( 5 -> 9 -> 2 )
- 617 + 295 の和を求めたい (答えは 912 )
- 出力: 2 -> 1 -> 9
- 912
- 入力: ( 7 -> 1 -> 6 ) + ( 5 -> 9 -> 2 )
答え
そもそも足し算はどのように行われるか確認しましょう。
手動計算
617
+295
----
912
- まず
7 + 5で 12 が得られます- 2 が 一の位
- 1 が繰り上がります
- 次に
1 + 1 + 9で 11 が得られます- 1 が 十の位
- 1 が繰り上がります
- 最後に
1 + 6 + 2で 9 が得られます- 9 が 百の位
- 答えは 912 になります
再帰的にノードの計算を行い、繰り上がりの数字を「次のノード」に渡せば OK です。
実装では次のような流れになります。
手動計算
7 -> 1 -> 6
+5 -> 9 -> 2
------------
2 -> 1 -> 9
- まず
7 + 5で 12 が得られます- 2 が最初のノード要素 (一の位)
- 1 が次のノードの足し算に持ち越される
- ここまでの連結リスト:
2 -> ?
- 次に
1 + 1 + 9で 11 が得られます- 1 が 2 番目のノード要素(十の位)
- 1 が次のノードの足し算に持ち越される
- ここまでの連結リスト:
2 -> 1 -> ?
- 最後に
1 + 6 + 2で 9 が得られます- 9 が最後のノード要素 (百の位)
- 完成した連結リスト:
2 -> 1 -> 9
LinkedListNode addLists(LinkedListNode l1, LinkedListNode l2, int carry) {
// 片方のリストがもう片方のリストより短い場合があるので注意する
// ※ null の参照によって例外発生しないようにする
if (l1 == null && l2 == null && carry == 0) {
return null;
}
LinkedListNode result = new LinkedListNode();
int value = carry;
if (l1 != null) {
value += l1.data;
}
if (l2 != null) {
value += l2.data;
}
// 余り算で、足し算の結果の一の位を取得
result.data = value % 10;
if (l1 != null || l2 != null) {
l1 = (l1 == null) ? null : l1.next;
l2 = (l2 == null) ? null : l2.next;
carry = (value >= 10) ? 1 : 0;
// 再帰実行
LinkedListNode more = addLists(l1, l2, carry);
result.setNext(more)
}
return result;
}
発展問題
上位の桁から順方向に連結されたリストを用いて、同様に解いてみてください。
- 例
- 入力: ( 6 -> 1 -> 7 ) + ( 2 -> 9 -> 5 )
- 617 + 295 の和を求めたい (答えは 912 )
- 出力: 9 -> 1 -> 2
- 912
- 入力: ( 6 -> 1 -> 7 ) + ( 2 -> 9 -> 5 )
答え
逆方向の連結リストでは、再帰の方向と同じ方向である「次のノード」に数字を渡せばよかったですが、順方向の連結リストではいくつか注意点があります。
- 片方のリストがもう片方より短い場合、そのまま足し算できない
- ( 1 -> 2 -> 3 -> 4 ) + ( 5 -> 6 -> 7 ) の場合
1 + 5ではなく、2 + 5をしないといけない- 5 から見た場合、2 こそが同じ桁であることが分かっていないといけない
- 各リストの長さを比較して、短いほうのリスト先頭に 0 を加えて長さを揃える必要がある
- ( 1 -> 2 -> 3 -> 4 ) + ( 0 -> 5 -> 6 -> 7 ) にする
- 繰り上がりの数字は「前のノード」に渡すことになる (再帰と逆方向)
- よって繰り上がりの数字だけではなく、結果を返す必要がある
// ラッパークラスを作成
public class PartialSum {
public LinkedListNode sum = null;
public int carry = 0;
}
LinkedListNode addLists(LinkedListNode l1, LinkedListNode l2) {
// ※ length() のコードは割愛
int len1 = length(l1);
int len2 = length(l2);
// 短いリストに 0 を詰める
if (len1 < len2) {
l1 = padList(l1, len2 - len1);
} else {
l2 = padList(l2, len1 - len2);
}
// リストを足す
PartialSum sum = addListsHelper(l1, l2);
// 繰り上がりがなければ、そのままリストを帰す
if (sum.carry == 0) {
return sum.sum;
// 繰り上がりが残っていれば、先頭に 0 を詰める
} else {
LinkedListNode result = insertBefore(sum.sum, sum.carry);
return result;
}
}
PartialSum addListsHelper(LinkedListNode l1, LinkedListNode l2) {
if (l1 == null && l2 == null) {
PartialSum sum = new PartialSum();
return sum;
}
// 小さい位を再帰的に足す
PartialSum sum = addListsHelper(l1.next, l2.next);
// 現在の桁に繰り上がりを足す
int val = sum.carry + l1.data + l2.data;
// 現在の桁の和をリストに追加
LinkedListNode full_result = insertBefore(sum.sum, val % 10);
sum.sum = full_result;
sum.carry = val / 10;
return sum;
}
/*
* リストに 0 を詰める
*/
LinkedListNode padList(LinkedListNode l, int padding) {
LinkedListNode head = l;
for (int i = 0; i < padding; i++) {
head = insertBefore(head, 0);
}
return head;
}
/*
* 連結リストの先頭にノードを挿入するヘルパー関数
*/
LinkedListNode insertBefore(LinkedListNode list, int data) {
LinkedListNode node = new LinkedListNode(data);
if (list != null) {
node.next = list;
}
return node;
}
回文
連結リストが回文かどうかを調べる関数を実装してください。
回文とは、先頭から巡回しても末尾から巡回しても、各ノードの要素がまったく同じになっているものです。たとえば 0 -> 1 -> 2 -> 1 -> 0 のような連結リストが「回文」になります。
答え
A: 並び替えと比較
リストを逆順にして、元のリストと一致していれば「回文」と判定できます。
boolean isPalindrome(LinkedListNode head) {
LinkedListNode reversed = reverseAndClone(head);
return isEqual(head, reversed);
}
LinkedListNode reverseAndClone(LinkedListNode node) {
LinkedListNode head = null;
while (node != null) {
// クローン
LinkedListNode n = new LinkedListNode(node.data);
n.next = head;
head = n;
node = node.next;
}
return head;
}
LinkedListNode isEqual(LinkedListNode one, LinkedListNode two) {
while (one != null, two != null) {
if (one.data != two.data) {
return false;
}
one = one.next;
two = two.next;
}
return one == null && two == null;
}
リストの前半部分が一致していれば、後半部分も一致していることになります。
B: 繰り返し処理
リストの前半分だけを逆順にして、後半部分と一致すれば「回文」と判定できます。
この場合はスタック (後入れ先出し) を利用できます。
スタックにはリスト前半部分を push します。
このとき、リストの長さが分かっている場合・分かっていない場合で実装方法が異なります。
- リストの長さが分かっている場合
- ループ文で順にスタックへ push すればよい
- リストの長さが奇数の場合は注意する
- リストの長さが分かっていない場合
- ファーストランナー・スローランナーが登場するランナーテクニックを利用する
- ファーストランナーがリスト終端にいるとき、スローランナーはリスト中間地点にいる
- スローランナーが指すノードをスタックに積んでおく
- スタックは「最後に格納した要素が最初に取り出される」
- → 中間の時点で、前半部分を「逆順」で取得することができる
- 中間地点からは、スタックから取り出した要素と比較を行う
boolean isPalindrome(LinkedListNode head) {
LinkedListNode fast = head;
LinkedListNode slow = head;
Stack<Integer> stack = new Stack<Integer>();
/*
* 連結リストの前半部分を要素をスタックに積む
* ファーストランナーは 2 倍の早さで移動するため、リストの終端に達したとき、
* スローランナーは中間地点になる
*/
while (fast != null && fast.next != null) {
// push: stack にデータを積む
stack.push(slow.data);
slow = slow.next;
fast = fast.next.next; // 2 倍の早さ
}
// 要素数が奇数の場合、真ん中の要素はスキップする
if (fast != null) {
slow = slow.next;
}
while (slow != null) {
// pop: stack からデータを取り出す
int top = stack.pop().intValue();
// 異なる値だったら回文ではない
if (top != slow.data) {
return false;
}
slow = slow.next;
}
return true;
}
C: 再帰的処理
ノードの表記方法
あるノードを Kx と表記するとしましょう。
- K はノードの要素
- x は f (front) か b (back) が入る
- f: 連結リストの前半から数えた場合
- b: 連結リストの後半から数えた場合
たとえば 2b は「連結リストの後半から数えて 2 番目の要素」となります。
リストの中央に向かって比較していく方法
多くの連結リストの問題は「再帰的な方法」で解くことができます。
- 0 番目の要素と n – 1 番目の要素を比較する
- 1 番目の要素と n – 2 番目の要素を比較する
- 2 番目の要素と n – 3 番目の要素を比較する
- i 番目の要素と n – i 番目の要素を比較する
このように「リストの中央に向かって比較していく方法」が思いつくかもしれません。
0 -> 1 -> 2 -> 3 -> 1 -> 0 のような連結リストだったら、0 ( 1 ( 2 ( 3 ) 2 ) 1 ) 0 となるイメージです。
この方法で実装したければ「中間地点に達する瞬間」を知る必要があります。
そこが初期状態になります。
// 連結リストの長さを引数にとる
recurese(Node n, int length) {
if (length == 0 || length == 1) {
// 連結リストの中間地点
return [something]
}
/*
* 再帰実行
* 「連結リストの長さ - 2」していくことで中間地点を発見する
*/
recurese(n.next, length - 2);
}
i 番目の要素と n – (i + 1) 番目の要素を比較する前に、
再帰実行でコールスタックがどうなるか考えてみましょう。
- v1 = isPalindrome: list =
0 ( 1 ( 2 ( 3 ) 2 ) 1 ) 0→ length: 7- v2 = isPalindrome: list =
1 ( 2 ( 3 ) 2 ) 1 ) 0→ length: 5- v3 = isPalindrome: list =
2 ( 3 ) 2 ) 1 ) 0→ length: 3- v4 = isPalindrome: list =
3 ) 2 ) 1 ) 0→ length: 1 (中間地点) - return 2b, v3 ※
(3f == 3b)の結果
- v4 = isPalindrome: list =
- return 1b, v2 ※
(2f == 2b)の結果
- v3 = isPalindrome: list =
- return 0b, v1 ※
(1f == 1b)の結果
- v2 = isPalindrome: list =
- return null, true
return では、次のノード (LinkedListNode) と比較結果 (boolean) を返してあげましょう。
の 2 つのメンバ変数を持つラッパークラスがあれば大丈夫です。
class Result {
public LinkedListNode node;
public boolean result;
}
boolean isPalindrome(LinkedListNode head) {
int length = lengthOfList(head);
Result p = isPalindromeRecurse(head, length);
return p.result;
}
Result isPalindromeRecurse(LinkedListNode head, int length) {
/*
* 中間地点判定
*/
// ノード数が偶数
if (head == null || length <= 0) {
return new Result(head, true);
// ノード数が奇数
} else if (length == 1) {
// 仮に head が 3 なら、head.next は 2b になる
return new Result(head.next, true);
}
// 部分リストを再帰的に処理する
Result res = isPalindromeRecurse(head.next, length - 2);
/*
* 中間地点の Result から処理されて、ノード先頭の処理に戻っていく
*/
// もし子要素が回文じゃなかったら、呼び出し元に失敗通知する
if (!res.result || res.node == null) {
return res;
}
// 判定結果と次のノードを設定する
res.result = (head.data == res.node.data);
res.node = res.node.next;
return res;
}
int lengthOfList(LinkedListNode n) {
int size = 0;
while (n != null) {
size++;
n = n.next;
}
return size;
}
交わるノード
2 つの (単方向) 連結リストが与えられるとき、
2 つのリストが共通かどうか判定してください。また共通するノードを返してください。
共通するというのは「そのノードの参照が一致する」ことであって、値の一致ではないとします。
※ ようするにオブジェクト同士のメモリ比較を行う
例えば 1 つ目の連結リストの k 番目のノードが、
2 つ目の連結リストの j 番目のノードと (参照によって) 完全一致した場合を「共通する」といいます。
答え
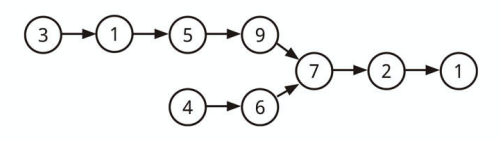
連結リストが交わった場合、上記のようになります。
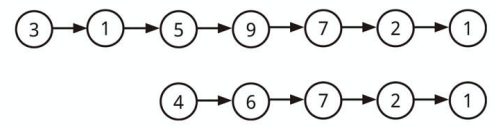
連結リストが交わらない場合、上記のようになります。
※ 連結リストがそれぞれ同じ長さになるのは特殊なケースなので、今は考慮しません。
交わる部分があるかどうかを判定する
2 つの連結リストが交わるかどうか、どのように判定すればよいでしょうか。
ひとつの方法として、連結リストの全ノードをハッシューテーブルに投入することができます。
その場合「ノードの値」ではなく「メモリ上の位置」で連結リストを参照するように注意しましょう。
もうひとつ簡単な方法があります。
2 つの連結リストで交わる部分がある場合、最後のノードは常に同じです。
よって連結リスト末尾から辿っていき、互いのノードを比較していけばよいことになります。
合流地点を見つける
連結リストが「枝分かれ」したときが、ノードの合流地点になります。
しかし、単方向の連結リストでは後ろからたどることはできないので、
連結リストの「長さの違い」から合流地点を判断します。
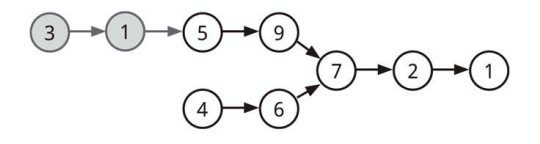
- 2 つの連結リストの長さが同じだったら
- 同時に調べていって、ぶつかったところが合流地点です。
- 2 つの連結リストの長さが違ったら
- 上記画像の余分な (グレー部分の) ノードを無視するか切り捨てましょう
- 2 つの連結リストの長さがわかっていれば、その差を切り捨てれば OK です
- 最初に連結リストの末尾を調べるとき、長さも同時に調べておけばよいでしょう
- 上記画像の余分な (グレー部分の) ノードを無視するか切り捨てましょう
まとめ
- 長さと末尾を得るために、各連結リストを走査する
- 末尾を比較する
- もし (値ではなく、参照が) 異なっていれば即 return する ※ 交わりなし
- 各連結リストの先頭に 2 つのポインタを置く
- 長い方の連結リストは長さの分だけポインタを進める
- 各ポインタが一致するまで連結リスト上を進んでいく
LinkedListNode findIntersection(LinkedListNode list1, LinkedListNode list2) {
if (list1 == null || list2 == null) return null;
// 末尾のノード、連結リストのサイズを得る
Result result1 = getTailAndSize(list1);
Result result2 = getTailAndSize(list2);
// 末尾のノードが異なっていれば、交わりはなし
if (result1.tail != result2.tail) {
return null;
}
// 各連結リストの先頭にポインタをセット
LinkedListNode shorter = result1.size < result2.size ? list1 : list2;
LinkedListNode longer = result1.size < result2.size ? list2 : list1;
// 長さの差の分だけ、長い方の連結リストのポインタを進める ※ 長さの差は「絶対値」でとる
longer = getKthNode(longer, Math.abs(result1.size - result2.size));
// 両方のポインタを進めながら、参照の比較を行う
while (shorter != longer) {
shorter = shorter.next;
longer = longer.next;
}
// どちらかを返す
return longer;
}
class Result {
public LinkedListNode tail;
public int size;
// コンストラクタ
public Result (LinkedListNode tail, int size) {
this.tail = tail;
this.size = size;
}
}
Result getTailAndSize(LinkedListNode list) {
if (list == null) return null;
int size = 1;
LinkedListNode current = list;
while (current.next != null) {
size++;
current = current.next;
}
return new Result(current, size);
}
LinkedListNode getKthNode(LinkedListNode head, int k) {
LinkedListNode current = head;
while (k > 0 && current != null) {
current = current.next;
k--;
}
return current;
}
2 つの連結リストの長さを A, B とすると O(A + B) の実行時間になります。
追加メモリは O(1) が必要になります。
ループの検出
循環する連結リストが与えられたとき、
循環する部分の最初のノードを返すアルゴリズムを実装してください。
- 循環を含む連結リストの定義
- 以下の連結リスト A ではループをつくるために、リスト内のノードの次へのポインタが以前に出現したノード C を指している
- 例
- 入力: A -> B -> C -> D -> E -> C ※ 最初の C と同じもの
- 出力: C
答え
パターンマッチングで解決することができます。
連結リスト内のループを検出する
ファーストランナー・スローランナーの 2 種類のポインタを使うことで、
連結リスト内のループを簡単に検出できます。
2 つのポインタが周回差で衝突するタイミングを得ることができれば OK です。
- ファーストランナー
- ノード間を 2 ステップ移動する
- スローランナー
- ノード間を 1 ステップ移動する
- ファーストランナーはスローランナーを (ぶつからずに) 追い抜いてしまうのでは?
- 仮に追い抜いたとき、スローランナーは i 番目・ファーストランナーは i + 1 番目です
- しかし、一つ前のステップでは、スローランナーもファーストランナーも i – 1 番目です
- つまり、ポインタ同士の衝突は必ず存在します。追い抜くことは問題になりません
いつ衝突するのか
いつ衝突が起きるのか考えてみましょう。
連結リストの「ループしていない部分」の長さを k, ループ部分の長さ LOOP_SIZE とします。
- スローランナーが p 進むとき
- ファーストランナーは 2p 進みます
- スローランナーが開始地点から k 進んで、ループ突入したとき
- ファーストランナーは開始地点から 2k 進んでいます
- ループ内ではは
2k - kで k だけ進んでいます- 2 つのランナーは
(LOOP_SIZE - k)ノード分、離れているともいえます
- 2 つのランナーは
- k は LOOP_SIZE より大きくなる可能性があります
- ループ内のファーストランナー位置 k は剰余を用いて mod(k, LOOP_SIZE) とします
- あるいは、ある整数 M に対して
k = K + (M * LOOP_SIZE)ともいえます
- あるいは、ある整数 M に対して
- ループ内のファーストランナー位置 k は剰余を用いて mod(k, LOOP_SIZE) とします
- ループ内にいるので、それぞれのポインタは 1 ステップで 1 ずつ遠ざかるとも近づくとも表現できる
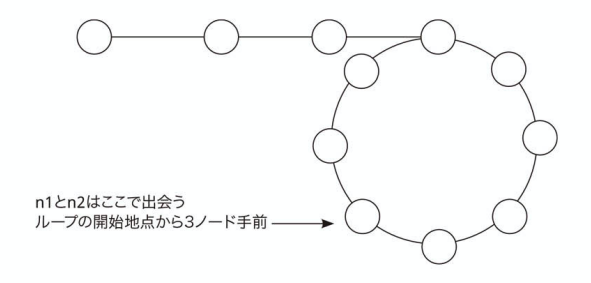
- スローランナーはループ内の 0 ステップ目にいる
- ファーストランナーはループ内の k ステップ目にいる
- スローランナーはファーストランナーの k ステップ後ろにいる
- ファーストランナーはスローランナーの
(LOOP_SIZE - k)ステップ後ろにいる - 一回の操作でファーストランナーはスローランナーの 1 ステップ追いかける
- つまり
(LOOP_SIZE - k)ステップ後に出会う → ループ開始地点の k ノード前が衝突点
どのようにしてループの先頭を探すか
ループ開始地点の k ノード前が衝突点になることがわかりました。
逆に「連結リストの先頭から k ノード先がループ開始地点」ということもわかっています。
はじめて衝突したら、スローランナーだけリストの先頭に戻して、
ファーストランナーはそのままにしましょう。
そのとき 2 つのランナーはループ開始地点から k ノード離れることになります。
次に 2 つのランナーを 1 ステップだけ進めていきます。
k ステップ進めたときに再度衝突できたら、それがループの開始地点のノードでしょう。
LinkedListNode findBegining(LinkedListNode head) {
LinkedListNode slow = head;
LinkedListNode fast = head;
/*
* 衝突点を発見する
* これは連結リストを (LOOP_SIZE - k) ステップ進んだ地点になる
*/
while (fast != null && fast.next != null) {
slow = slow.next;
fast = slow.next.next;
// 衝突
if (slow == fast) {
break;
}
}
// エラーチェック: 衝突点がない ※ つまりループが存在しない
if (fast == null || fast.next == null) {
return null;
}
// slow を連結リストの先頭に戻す ※ fast は衝突点に残す
slow = head;
/*
* slow も fast もループ開始地点から k ノード離れている
* 同じ早さで移動すると、ループ開始地点で出会う
*/
while (slow != fast) {
slow = slow.next;
fast = fast.next;
}
// どちらのポインタも「ループ開始地点のノード」が設定されている
return fast;
}
CS シリーズ
次回
前回
お仕事ください!
僕が代表を務める 株式会社 EeeeG では Web 制作・システム開発・マーケティング相談を行っています。 なにかお困りごとがあれば、Twitter DM や Web サイトからお気軽にご相談ください。
カテゴリ「CS」の最新記事
 【ロードマップ】文系の元ラーメン屋が学んだコンピュータサイエンス
【ロードマップ】文系の元ラーメン屋が学んだコンピュータサイエンス  【データ構造】「木とグラフ・探索アルゴリズム」をわかりやすく解説
【データ構造】「木とグラフ・探索アルゴリズム」をわかりやすく解説  【データ構造】キューとスタックの使い方を解説!【実用例たっぷり】
【データ構造】キューとスタックの使い方を解説!【実用例たっぷり】  【データ構造】面談対策!文字列・配列の問題解説【ハッシュテーブル】
【データ構造】面談対策!文字列・配列の問題解説【ハッシュテーブル】  TerraformによるLinodeインスタンス新規作成サンプル
TerraformによるLinodeインスタンス新規作成サンプル  【Fingerprint】CircleCIがSSHできない問題解決
【Fingerprint】CircleCIがSSHできない問題解決  【Laravel】セッションタイムアウト後のログイン処理で前回URLに遷移するバグ修正
【Laravel】セッションタイムアウト後のログイン処理で前回URLに遷移するバグ修正  M1 Mac(2021)でanyenv/phpenvの初期設定!
M1 Mac(2021)でanyenv/phpenvの初期設定! 










コメント